Reasoning Abilities of LLMs:
In-depth Analysis on the ARC
I. Motivation
What is Reasoning? Reasoning is defined in Cambridge Dictionary, as follows:
reasoning
noun /'ri:.zən.ɪŋ/the process of thinking about something in order to make a decision:
Fodor’s Language of Thought Hypothesis (LoTH) suggests human reasoning is based on Logical Coherence, Compositionality, and Productivity.
what is...
Logical Coherence?To help you understand, try solving the simple ARC puzzle below.
Pick the color and click the blank square
Can you see how each pattern changes? Since the input-output pairs share same pattern, we can say the pairs are logically coherent.
what is...
Compositionality?Compositionality refers to the ability of a system to combine simple ideas or functions into more complex ones.
In the images below, you can sequentially apply functions like move and flip to create the outputs on the right.
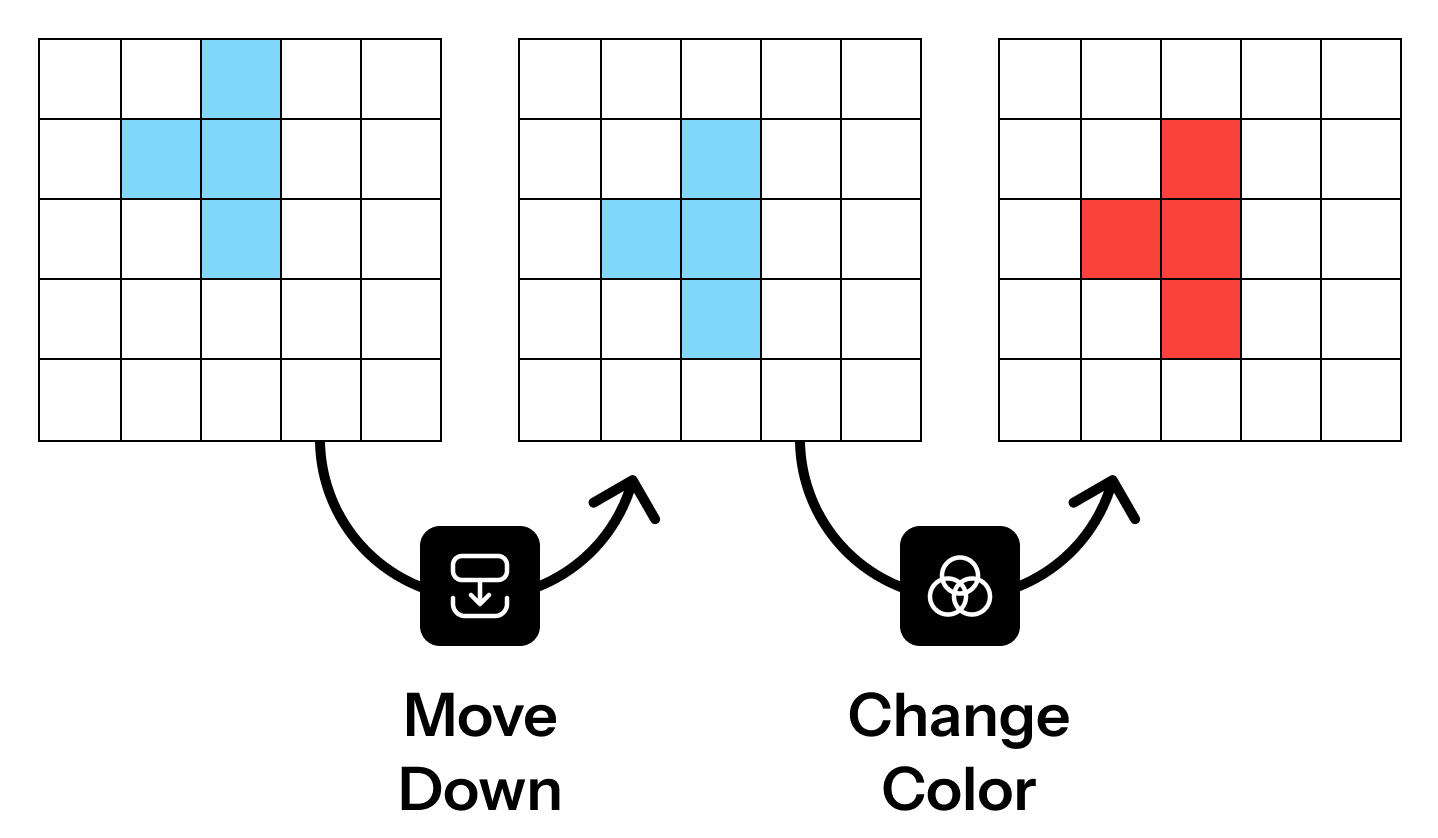
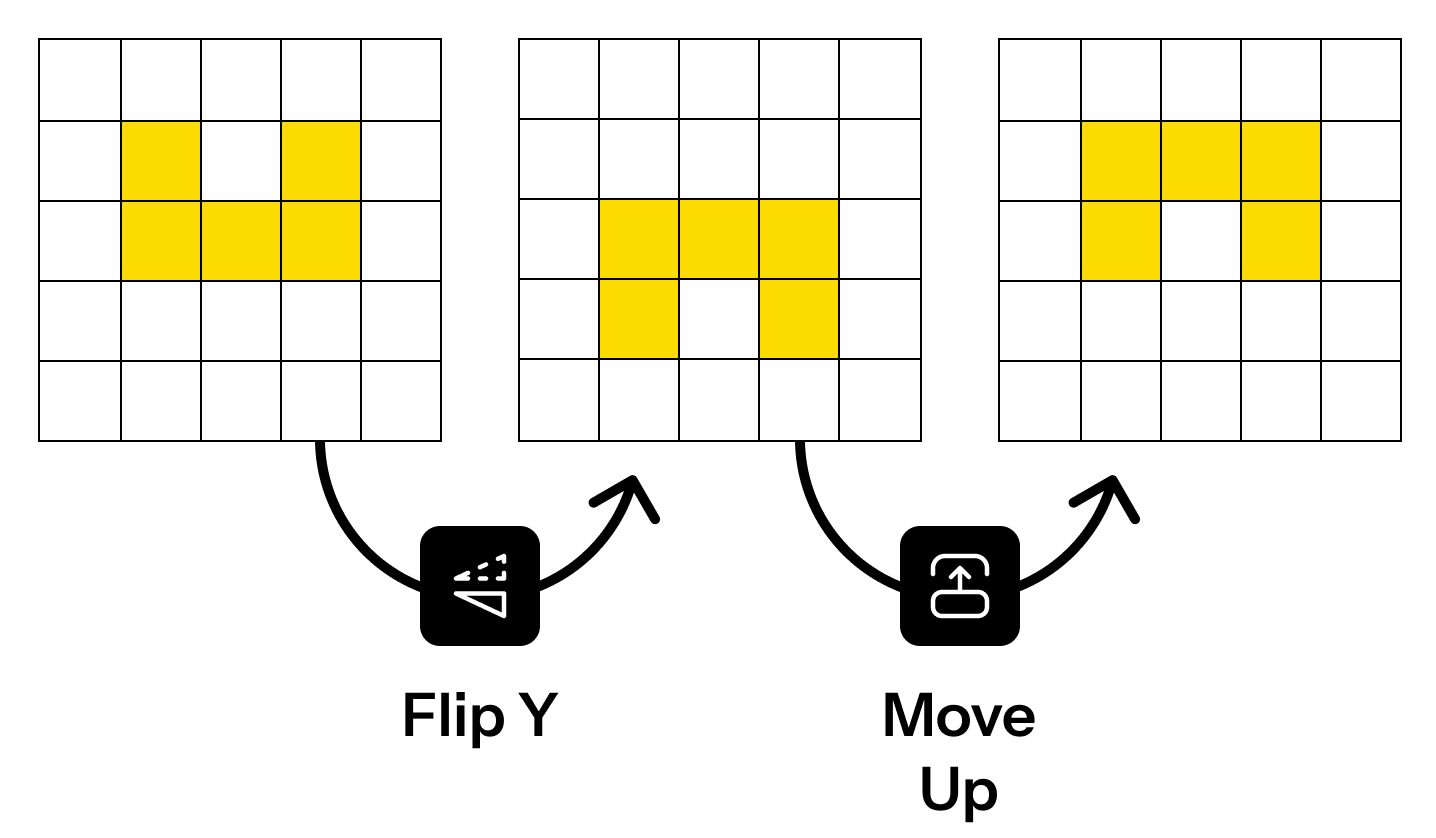
Then, can you combine given functions to make the goal below?
Click button below to apply
Great! You just recognized how the pattern changed and discomposed the change into some composition of functions.
The functions you just used (like move, flip, etc.) are called as Domain Specific Languages (DSLs) and will be mentioned in later experiments.
what is...
Productivity?Productivity, in the context of the LoTH, refers to the ability to generate novel solutions or representations from a finite set of rules or elements.
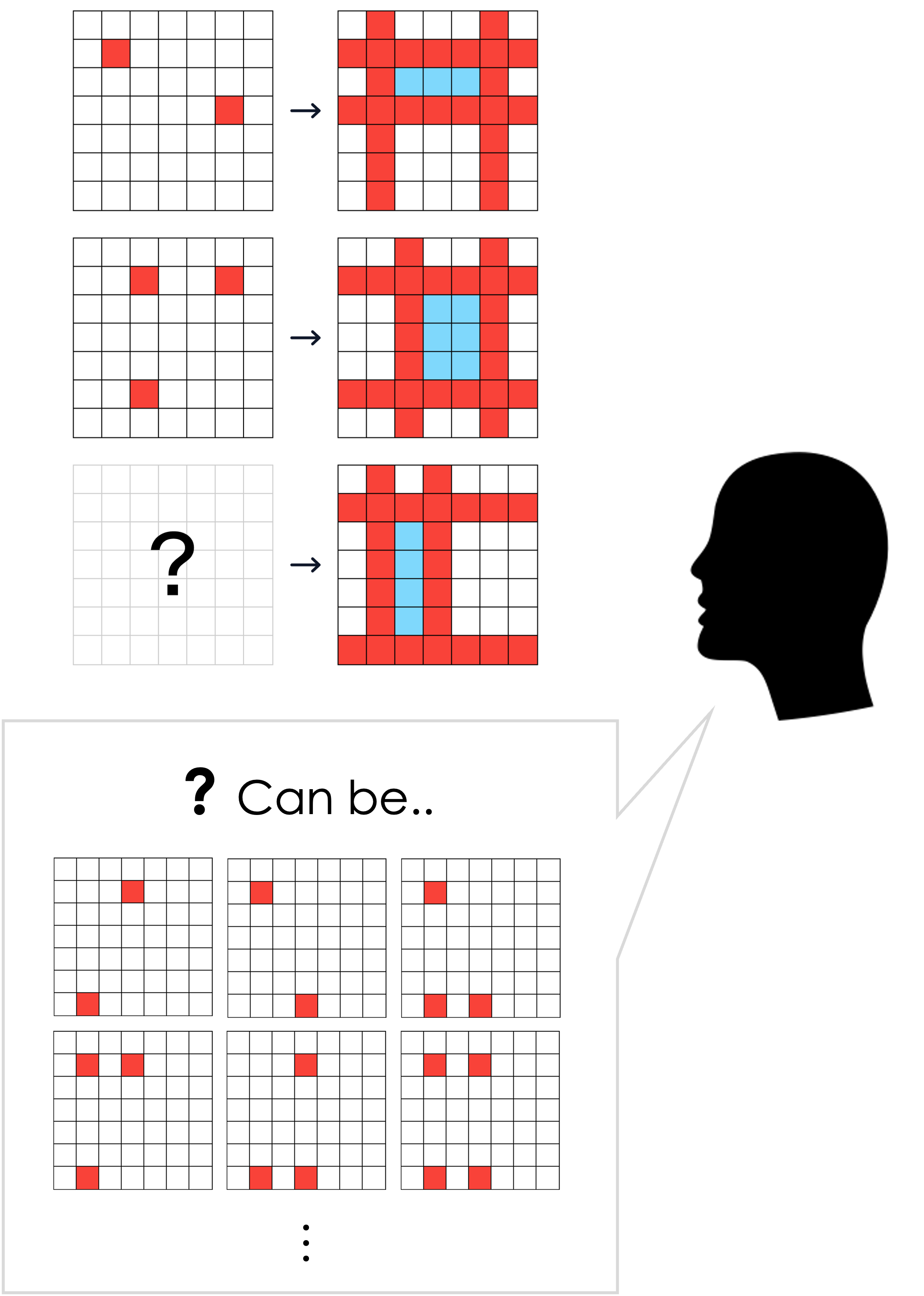
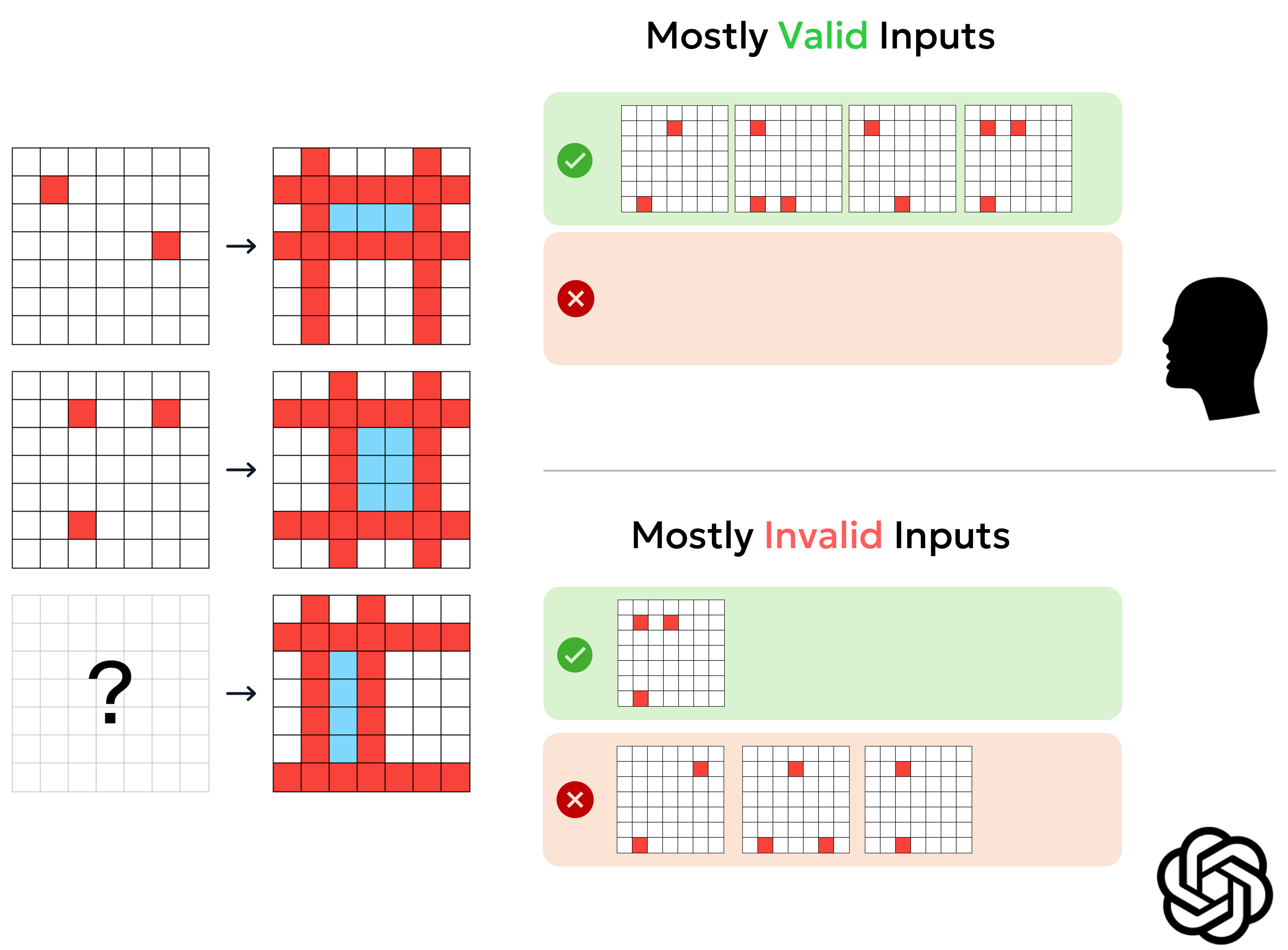
Do you remember the first puzzle in the Logical Coherence section? Given the same pattern of change, can you pick out all possible inputs from the output below?
Select all possible answers
As you solved the puzzle above, you can actually imagine (or produce) possible inputs from a given output.
II. Logical Coherence
Using Re-ARC, we augmented 100 new test pairs for each task that GPT successfully solved. These augmented test pairs preserved the original analogical rule, allowing us to consistently assess LLM’s ability to apply the rule with inferential coherence across varied instances.
Results show that while LLMs can sometimes arrive at the correct solution for an ARC task, their reasoning process is often flawed. We observed that LLMs could solve some tasks correctly but for the wrong reasons, indicating a lack of semantic coherence.
III. Compositionality
To measure compositionality, we provided LLM with information about Domain-Specific Languages (DSLs) and asked them to solve given ARC tasks. If an LLM possesses sufficient compositionality, it should be able to select appropriate DSLs and their arguments for a given goal.
The experiments showed that LLMs achieved low accuracy in solving ARC tasks using DSL, with only 3% accuracy when given just the DSL. In contrast, same experiment conducted with human approximated 86% accuracy.
IV. Productivity
For LLMs, productivity is assessed by their capacity to infer unseen patterns from existing ones and apply those patterns to generate valid new examples.
The experimental results showed that LLMs struggled with productivity in the context of ARC tasks. Out of 2,913 generated examples, only about 17.1% were deemed valid according to human judgment. LLMs often failed to infer meaningful rules from given example pairs, instead resorting to simply copying inputs.
V. Abstract
Large Language Models (LLMs) have recently demonstrated impressive capabilities across a range of natural language processing tasks. However, a fundamental question remains: to what extent do these models exhibit genuine reasoning abilities? In this study, we focus on understanding the inference processes of LLMs through an in-depth evaluation of their reasoning capabilities on tasks drawn from the Abstraction and Reasoning Corpus (ARC). Our approach takes inspiration from the “Language of Thought” Hypothesis (LoTH), which posits that human reasoning is built upon three core components: logical coherence, compositionality, and productivity. By evaluating LLMs on these three dimensions, we aim to provide insights into their reasoning strengths and limitations. Through this extended abstract, we highlight key experimental results that illuminate the capabilities and limitations of current LLMs in tasks requiring advanced cognitive reasoning.